Using content analysis, we analyse speeches of President Poroshenko from March 2015 to May 2016. We present the visualised word cloud and find the semantic content of president foreign speeches are similar to the domestic ones. Further, we investigate audiences’ education level measured by the readability and complexity of the texts. We also analyse political spectrum for each speech, and the results show that the domestic speeches have a bias to left-wing politics, while foreign speeches are more right-wing.
Why do we care about speeches of politicians and government officials? The hope is that they observe “my word is my bond,” that they will honor their promises, that they actually mean what they say. As a result, every word in a major speech is examined most carefully by journalists, political scientists, and the public. In the past, such analyses were often done with a tangible element of subjectivity, and interpretations differed.
With the development of computer science, new content analysis methods (topic model, Wordscore, machine learning, big data mining) have been developed to provide more objective readings of available texts. Indeed, researchers can now analyze massive amounts of textual information and systematically identify its properties.
We use these novel techniques to examine speeches of Petro Poroshenko, the President of Ukraine. From the official website, we collected all speeches in English as of 1 June 2016. The first speech is dated by 16 March 2015, and the last speech was published on 23 May 2016. In total, we downloaded texts of 30 speeches, 19 of which (63%) were given in front of foreign media or politicians (e.g. during visits abroad) and 11 — in front of Ukrainians (e.g. the Parliament).
Our analysis aims to accomplish several objectives. First, we provide a visualised overview of the word cloud and employ the so-called latent Dirichlet allocation (LDA) method to detect any additional or latent topics. Second, we calculate the similarity between the speeches made abroad and in Ukraine to check if the message is the same for domestic and foreign audiences. Third, we use a readability measure to assess whether the speeches are accessible to the public. Finally, we employ “Wordfish” to find president’s policy position.
The simplest technique to analyse texts is called word cloud that visually shows frequently mentioned words. Figure 1 provides a snapshot of “speech data” which shows top 50 features based on the term-document matrix. Further, Latent Dirichlet Allocation (LDA) is a generative statistical model that allows sets of observations to be explained by unobserved groups that explain similarities in some parts of the text. For example, the LDA model might identify humanitarian cooperation-related topics using probabilities of such words, such as “humanitarian”, “Ukraine”, “important”, “chancellor”, “German”, “support” and “like”. These words are found as top five latent topics in the speech from March 16, 2015. There are also a few differences between all the speeches addressed to foreign and local audiences. The latter one received on average 104 sentences, while a speech in front of the foreign public has on average 54 sentences.
Figure 1. Word Cloud for Ukraine President Speeches

President Poroshenko gave speeches both in Ukraine and abroad. To check whether there is any similarity between them we introduce the cosine similarities index. Cosine similarity is a measure used to assess the similarity of meaning or semantic content. If two texts are not similar, the index is equal to the 90-degree angle (that is, the texts are “orthogonal”), while complete similarity results in the 0-degree angle (that is, complete overlap of texts). Values between 0 and 90.0 indicate intermediate similarity or dissimilarity. For example, cosine similarity between “Ukraine” and “Ukraine” is 0, while the word “Russian” has a cosine distance of only 0.7 of a degree from “Ukrainian,” the highest similarity of any other country (EU, US, etc.). We find that the cosine distance is 0.823 out of 90.0, which means that there are high similarities for these two types of speeches. Thus, the President delivers a consistent message at home and abroad.
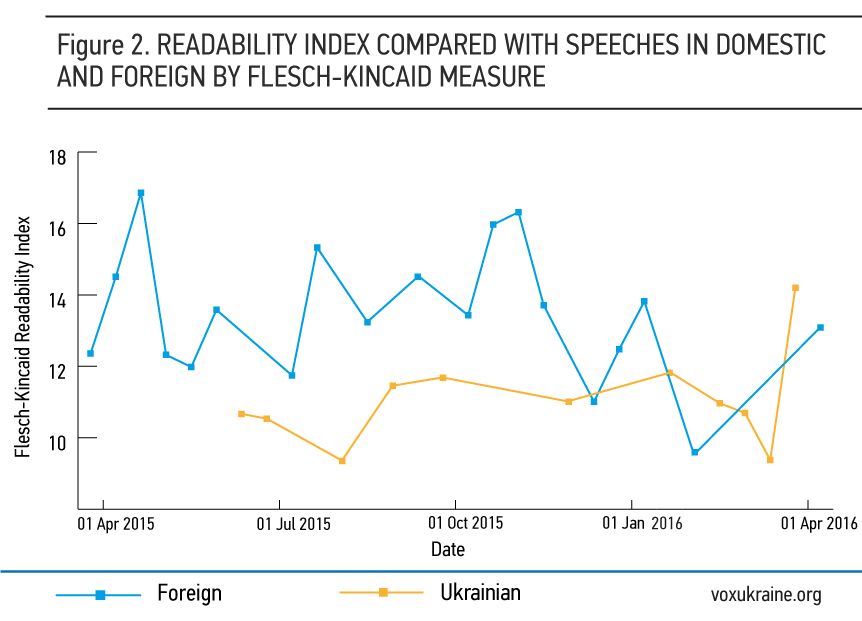
Next, we employ the Flesch-Kincaid readability index to measure the complexity of President Poroshenko’s speeches. This index indicates the level of education required for understanding a speech. A high value of the index indicates low readability (that is, a speech is hard to understand) as it takes more years of education to comprehend. Figure 2 shows that how Flesch-Kincaid readability index (y-axis) evolved for all the speeches (x-axis). Generally, the speeches were understandable for an audience with 10 to 16 years of education (10 years of schooling is approximately high school; 16 years of schooling is a college degree). We can see that the average readability level of speeches for foreign media or politicians is lower than it is for Ukrainians, which means that the president targets a higher education level for foreign audiences. However, the President delivered a lower readability (14.20) address on the occasion of the second anniversary of resistance to the Russian occupation of Crimea on 26 February 2016. The speech declared that Crimea was and would be an integral part of Ukraine. It is harder to understand due to the usage of seldom used words and reliance on special knowledge (e.g. “Anschulss” or “Karaites”). In total, the lowest readability (16.86 of Flesch-Kincaid) of speech was taken place on 27 April 2015 at the 17th EU-Ukraine Summit. The speech on 17 July 2015 (President Poroshenko accused Russian-backed militants of shooting down Malaysia Airlines flight MH17) had the highest readability (9.34 of Flesch-Kincaid).
It is conventional to describe political spectrum as ranging from the left wing to the right wing. Communism and socialism are typically considered internationally as being on the left, while fascism and conservatism — on the right. Wordfish is a word scaling algorithm to estimate political positions based on word frequencies in textual information (Slapin and Proksch, 2008). Figure 3 shows the position estimates for the domestic and foreign speeches from the Wordfish model. The vertical axis represents the scale of estimated position from left to right (positive value to negative), with zero meaning ambiguity. The horizontal axis shows the time when the President delivered his speech. It can be seen that political positions tend to be tilted to towards the left wing when the President gives speeches in Ukraine, while some of the speeches for foreign media or politicians are more likely to be on the right. The domestic speeches delivered on 17 July 2015 and 30 October 2015 moving towards the political right, which addressed flight MH17 shooting down and the solidarity with France after terrorist attacks representatively. These events could let the president take conservative positions. Also, the far left position is on 04 June 2015 made in front of Ukrainians.
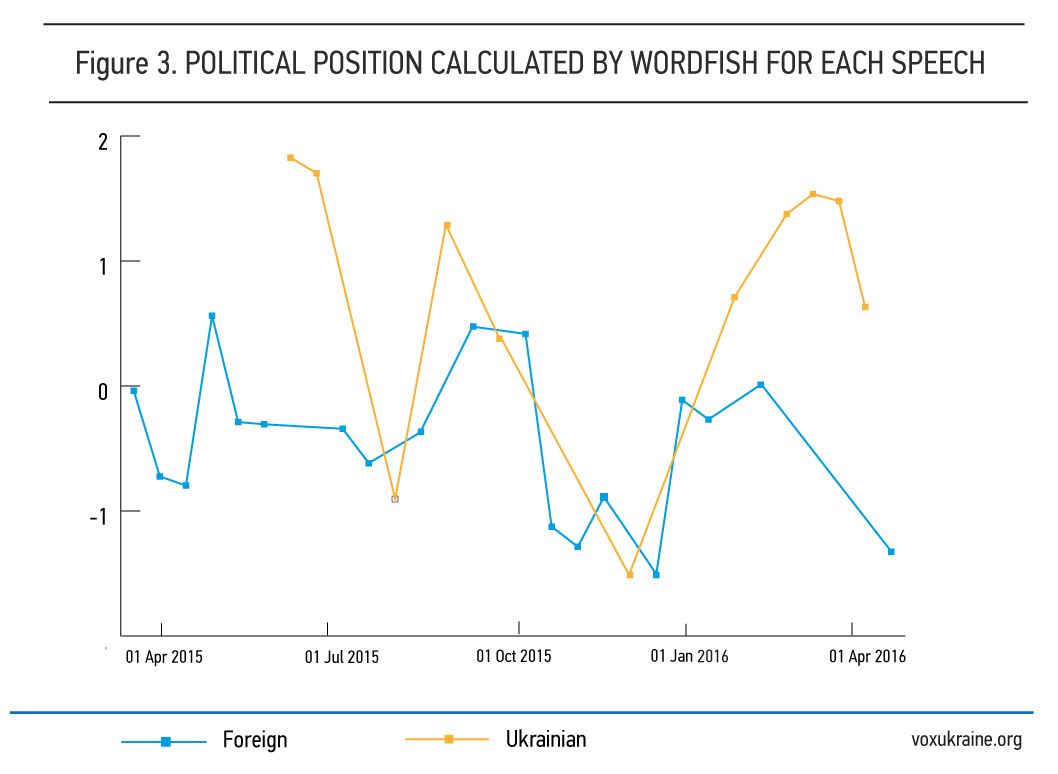
In conclusion, we statistically analyse textual information from President Poroshenko’s speeches. The speeches are written using a simple language so that a typical person can understand the meaning. However, speeches addressed abroad are more complex, which means that international conferences or invited talks target a higher level of audiences. The message is similar for the foreign and domestic audience. The rhetoric of President Poroshenko tends to be on the “left” of the political spectrum in front of Ukrainians and slightly “right” in front of foreign media or politicians, although there is some variation over time. There are also different policy positions associated with certain topics and situation. For example, economic and societal topic shows a left wing, while accused terrorist attacks tend to more right wing.
References:
1. Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet allocation. Journal of Machine Learning Research, 3(Jan), 993-1022.
2. Laver, M., Benoit, K., & Garry, J. (2003). Extracting policy positions from political texts using words as data. American Political Science Review,97(02), 311-331.
3. Slapin, J. B., & Proksch, S. O. (2008). A scaling model for estimating time‐series party positions from texts. American Journal of Political Science, 52(3), 705-722.



Attention
The authors do not work for, consult to, own shares in or receive funding from any company or organization that would benefit from this article, and have no relevant affiliations


